Bucketed Ranking Loss for Efficient Ranking-based Training of Object Detectors
Background
A detector scores every candidate box with a logit \(x\). Score-based losses (cross-entropy, focal) treat boxes independently and must fight the extreme foreground/background imbalance with tuned weights. Ranking-based losses instead optimize the order of scores, which matches how Average Precision is computed and is imbalance-robust by construction. Their shared primitive is a pairwise comparison between every positive \(i\) and every negative \(j\) through a (relaxed) Heaviside step \(H\), \[ p(i, j) = H(x_j - x_i), \qquad \mathrm{rank}^-(i) = \sum_{j \in \mathcal{N}} H(x_j - x_i), \] so the ranking error of a positive grows with \(\mathrm{rank}^-(i)\), the number of negatives scored above it; RS Loss adds a sorting term over the positives.
The cost
Evaluating this for all pairs is \(O(PN)\) with \(P=|\mathcal{P}|\) positives and \(N=|\mathcal{N}|\) negatives. For ATSS on COCO, \(N \approx 10^8\), so the \(P \times N\) matrix has about \(10^{16}\) entries and cannot fit on a GPU. This is why ranking losses, despite their accuracy, stayed impractical for large-scale and transformer detectors.
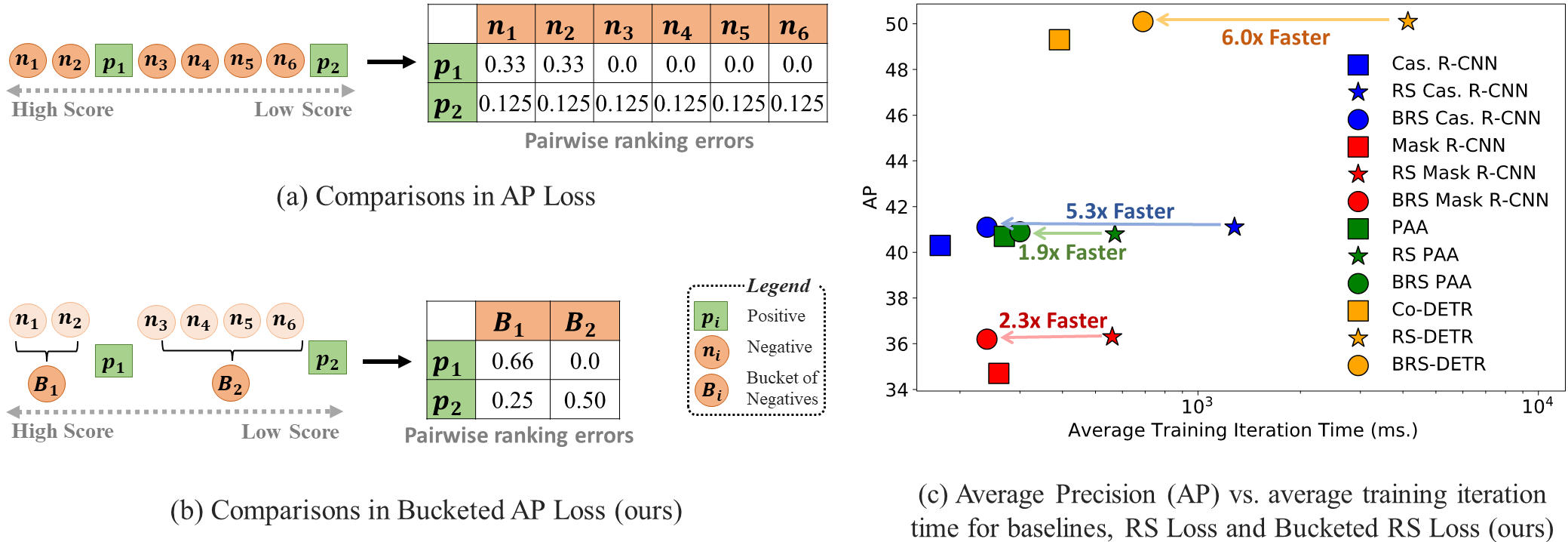
Bucketing
After sorting all logits, long runs of negatives between two positives share almost the same score. Bucketed RS/AP Loss groups them into \(B\) buckets, each represented by a prototype equal to its mean logit, \[ \bar{x}_b = \frac{1}{|b|} \sum_{j \in b} x_j, \qquad B \le 2|\mathcal{P}| + 1, \] and compares only the \(P\) positives against the \(B\) prototypes. Sorting now dominates, dropping the cost to \(O(\max(N \log N,\, P^2))\); each prototype gradient is divided by its bucket size and distributed to the members. With smoothing width \(\delta = 0\) the bucketed loss has exactly the same gradients as the original (their Theorem 4.1), and stays empirically identical for \(\delta > 0\), so accuracy is preserved.
Results
On COCO the bucketed losses preserve accuracy while training about \(2\times\) faster on average; the loss computation itself is up to \(40\times\) faster in isolation. Accuracy is matched across detector families:
| Detector (ResNet-50) | Baseline AP | Bucketed AP | Train speed-up |
|---|---|---|---|
| Faster R-CNN | 39.4 | 39.5 | ~2x |
| Cascade R-CNN | 41.1 | 41.1 | up to 6x |
| ATSS | 39.8 | 39.8 | ~2x |
| PAA | 40.4 | 40.4 | ~2x |
| Mask R-CNN (mask AP) | 35.6 | 35.7 | ~2x |
It also brings ranking losses to transformer detectors for the first time. Built on Co-DETR, BRS-DETR improves AP while cutting the loss step from \(4.14\)s to \(0.69\)s per iteration (\(\approx 6\times\)):
| BRS-DETR backbone | Co-DETR AP | BRS-DETR AP | Gain |
|---|---|---|---|
| ResNet-50 (12 ep) | 49.3 | 50.1 | +0.8 |
| Swin-T | 51.7 | 52.3 | +0.6 |
| Swin-L | 56.9 | 57.2 | +0.3 |
Ranking losses also expose far fewer hyperparameters than score-based losses (one versus five to nine), which removes most of the per-detector tuning.